Diffusion Language Models -- Part Three (Generating with DLMs; through some art & linguistics)
September 1, 2025
Generating text with DLMs is quite different from doing so with AR-LLMs, and in my earlier posts here and here I have sketched a brief outline of how it works for Masked-DLMs (using a Wheel of Fortune analogy). In this post, I will go a little deeper into the generation process and examine a number of limitations/challenges there, together with what has been recently proposed for addressing them. This post also starts with a slightly different flavour, a light detour from the so-far technical posts with a foray covering interesting artwork I saw recently, with associations to DLMs and which brought out connections to ideas in linguistics; I was thinking that starting this way could help ground the technical aspects of DLMs to some visual concepts which might aid in understanding these technical aspects. This post is a little delayed as I was engaged in some community duties and it also took some time to take a deeper investigation into some of the works covered in this post.
🖼️ 1. Seeing DLMs through art and linguistics
In July, I visited the Heman Chong retrospective at the Singapore Art Museum, and encountered a piece of work that made me smileIn fact, quite a few of Chong’s pieces at the retrospective brought a smile to my mind; it was a very pleasant visit for being thought-provoking on a number of levels. I do think his work deserves more local (Singaporean) appreciation (they are highly incisive commentaries, many with complex multi-layered abstractions of remarkable spareness that slowly unfurl in your mind; and are world-class with a Singaporean flavour to them). and also immediately made me think of DLMs.

Call for the Dead, 2020, Screenprint and acrylic on linen, Collection of the artist
“While on residency at STPI (Singapore Tyler Print Institute) in 2020, Heman Chong read and then redacted John le Carré’s first book, Call for the Dead… Erasing everything except for its verbs, Chong’s Call for the Dead leaves us only with a sense of something having happened and the awareness that the text holds secrets not meant for us.”

The work (close-up in the image above, and a wide-shot of the hanging in the right margin) is titled “Call for the Dead” and is the text of a John le Carre novel that Chong had meticulously blacklined throughout to mask every single word except for the verbs. What immediately struck me was how there is a liminal quality to the work: at once filled with meaning yet poised for more – the state of the text shown permits/carries potential, similar to being in the midst of complete masking/unmasking in the forward/reverse process. What also struck me as I got close to the work was how, despite there only being verbs remaining, I could still reasonably make out the narrative arc of the text (the numbers and lengths of the masked words did help in the decoding), and that brought to mind DavidsonianThe view that sentence meaning is quantified over events denoted by verbs; verbs whose arguments are filled by the participants of the event; for e.g. the sentence “Chong masked words from the book” can be represented as: \(∃e(mask(Chong, words, e)\) ∧ \(from(words, book, e))\) or equivalently “There exists some event \(e\) where a masking action by Chong on words takes place, and the words are from the book in \(e\)“. See (Filip, 2013) for a nice set of notes on Davidsonian event semantics.
Sidenote: this is a nice paper where visual question answering, scene graphs and Davidsonian semantics come together for interpretable verification of the contents of generated outputs (Cho et al, 2024) and neo-Davidsonian event semantics! This was also the inspiration for wondering in the previous post which set of word types a DLM would be most confident in unmasking at the start of the reverse process.For conditional generation, a reasonable hypothesis is that this set might be a mix of verbs and proper nouns (i.e. entities in the context/prompts), but it would be interesting to verify this over a few Masked-DLMs to better understand what/how a DLM might be learning and generating. Sometimes there can be connections between art, linguistics and computer science in quite beautiful ways.Another is Alexander Calder’s mobiles, whose elements hang in balance, suspended in place like constituent syntax trees of an utterance. And another is Lim Hsin Hsin a trailblazing (on so many levels: female multi-disciplinary artist formally trained in mathematics and computer science practising from the 1970s in Singapore) artist whom I recently learned about at the latest iteration of the National Gallery’s permanent exhibition of Singapore art.
🎲 2. Masked-DLMs: Since we mask randomly in the forward process,
why not just unmask randomly in the reverse process too?
We mask tokens randomly in the forward process for training Masked-DLMs, and this is what allows the DLM to learn so that we can do any-order/non-autoregressive generation in the reverse process. Therefore, it is natural to also think of doing the unmasking in the reverse process in a similarly random manner i.e. at each timestep \(t\), randomly choose a K-sizedi.e. K = sequence length / number of denoising steps set of still-masked index positions to be unmasked by the model (Austin et al, 2021).
However, this is sub-optimal; especially if we follow the “classical” Masked-DLM formulation (i) where, once a token is unmasked it stays fixed in that state, and (ii) if we take large steps to unmask much more than a single token at each step, both of which would come together to give poorer generation quality. A key reason for this is because, when taking steps of \(\gt\) 1 tokens in the reverse process, the dependence of the tokens being unmasked are not taken into account, due to how Masked-DLM models are parameterised.For details, see the paragraph under the “Multi-dimension” subheader in §2.1 of (Ou et al, 2024) and §3.3 of (Lou et al, 2023). Hence, if 100 tokens have to be unmasked at a step, it is quite possible that some of them could be incompatible with each other. The worst case scenario is when the incompatible tokens unmasked in the same step are located next to or close to each other in terms of sequence positions, which would leave little leeway for recovery in the later steps from the incompatibility. Such errors compound and could lead to increasingly less coherent text.
The most obvious solution for this would be to take small steps (and the safest would be to take a step of only one token at a time). Another easy solution could be to take smaller steps initially to try to avoid early irreversible clashes before increasing the step size over time. However these simple fixes are inadequate,The former entirely removes a major appeal of DLMs, which is its potential for “parallel decoding” to achieve faster generation speed; whereas the latter does not fully address the token independence issue in a principled manner – it would surface at later larger steps and hence could still lead to issues with generation quality. and the following are two more sophisticated directions that have been proposed:
◼️ top-k confidence: Since Masked-DLMs parameterise the probability distribution over the vocabulary for each sequence position (\(0 \leq i \leq L\), where \(L\) is the length of the sequence to be generated), it makes sense to adopt a “top-k” strategy over the model’s highest confidence at each position.Note that this is different from the top-k sampling in AR-LLMs, where for a given token to be generated it is sampled from the set of top-k tokens with the highest probabilities; here it refers to the top-k sequence positions with the highest probability values in their distributions. This was used in (Zheng et al, 2024) and recently systematically studied in (Kim et al, 2025). However, the top-k strategy loses its effectiveness in instances where the model has similar confidence (i.e. uncertainty) at some positions, and to address that (Kim et al, 2025) proposed “top-k margin confidence”.Here, the margin of the top-2 most probable tokens at each position is computed and is used to select the top-k subset for unmasking. This approach leaves out sequence positions that may have a high probability value in it, but where the model has uncertainty between its most probable tokens. This approach has been shown to improve generation quality meaningfully and these methods have been incorporated as options in the LLaDA (Nie et al, 2024) and Dream (Ye et al, 2025) scripts.
◼️ allowing corrections: Another direction is to allow corrections to be made to the already unmasked tokens, instead of keeping them fixed entirely. The corrections could come (i) via remasking, or (ii) using a setup with a specialised model.
◽️ The former, also referred to as “forward-backward” correction, involves picking a subset of the already unmasked tokens – early approaches picked these by randomly sampling – and returning (hence the “backward”) them to the masked state. Doing so allows another shot at unmasking them to appropriate tokens, since the model can now take into consideration the other tokens already unmasked (including the ones in the same step as it). Notably, it has been shown by (Wang et al, 2025) that it is not necessary for special training procedures to use such remasking.Their work outline a set of proofs showing that an already trained Masked-DLM can be used with remasking in a theoretically-supported manner; subject to the Masked-DLM having been trained with a negative ELBO tighter than the one for ReMDM that they specify (see §3.2 of their paper). Note also that remasking permits a reverse process with more steps than the sequence length \(L\), which has analogues to test-time scaling in AR-LLMs (Snell et al, 2024).Without remasking, i.e. masked tokens stay masked, hence once all of the sequence positions are unmasked, further steps have no effect. With remasking, this constraint is removed and can be seen as a form of test time-scaling for DLMs; this shares parallels with how additional generation steps in AR-LLMs, for e.g. “think” tokens (that do not count towards the answer) have been shown to improve AR-LLMs’ answer performance. The drawbacks with remasking are that: (i) using random sampling for tokens to remask, or “uninformed correction”, is not optimal as it does not directly target the tokens that need correction and could even miss themTo this, (Wang et al, 2025) also examined a few ways for selecting the tokens to be remasked (“informed correction”), including a customisable approach (ReMDM-conf) that is (1) based on the confidence the model had when unmasking a token, and (2) which can be activated at points of the reverse process where remasking is most helpful., and (ii) remasking does add inference overheadGiven some fixed number of tokens to unmask per-step, setting a portion to remask at each step increases the number of steps required..
◽️ On the other hand, the second approach such as the one proposed by (Zhao et al, 2024), involve a separate model that can be designed to identify and predict for the direct transitioning of certain unmasked tokens to another non-mask token. The appeal here is that this does away with having to do the superfluous transition to the mask token first, before transitioning to another prediction for the token. However, needing a separate model comes with the drawback that it adds to both training and inference overhead.
Nonetheless, it should be possible to combine these approaches for Masked-DLM generation without negative effects on quality, i.e. use top-k confidence to select which positions to unmask as well as allow for correction with remasking.
🖇️ 3. Are there alternatives to independent token-level unmasking?
Since large-step parallel decoding in Masked-DLMs is sub-optimal (due to the independence of the tokens unmasked at every such steps; see above) this acts as a limit to faster decoding (i.e. generating with fewer denoising steps). As such, some work have examined how to mitigate this, including two that share some similarities with draft-model based speculative decoding in AR-LLMs (Leviathan et al, 2023),Broadly, this approach involves using a small AR-LLM (of the same architecture but with fewer parameters hence faster to run; the ‘draft model’) to auto-regressively generate multiple (\(K\)) tokens ahead of the larger and more capable AR-LLM used to generate the output (‘target model’). It involves putting the \(K\) draft tokens through the target model (any speed-up is due to this: by computing probabilities for multiple tokens in parallel instead of one at a time) and accepting the draft tokens up the token before the predictions (based on probabilities) of the draft and target LLM depart, and then generating +1 token from the target model; if there is no departure, all tokens are accepted. Generation then continues with the draft model proposing the next \(K\) tokens.
Sidenote: Here’s a nice blog post recently written by the authors of (Leviathan et al, 2023); the AI search summaries on Google’s search results page are served with the help of speculative decoding! This vLLM blog post is also a good read. in the sense that all these approaches leverage two models (one larger and one usually smaller, more efficient one) to improve generation quality.
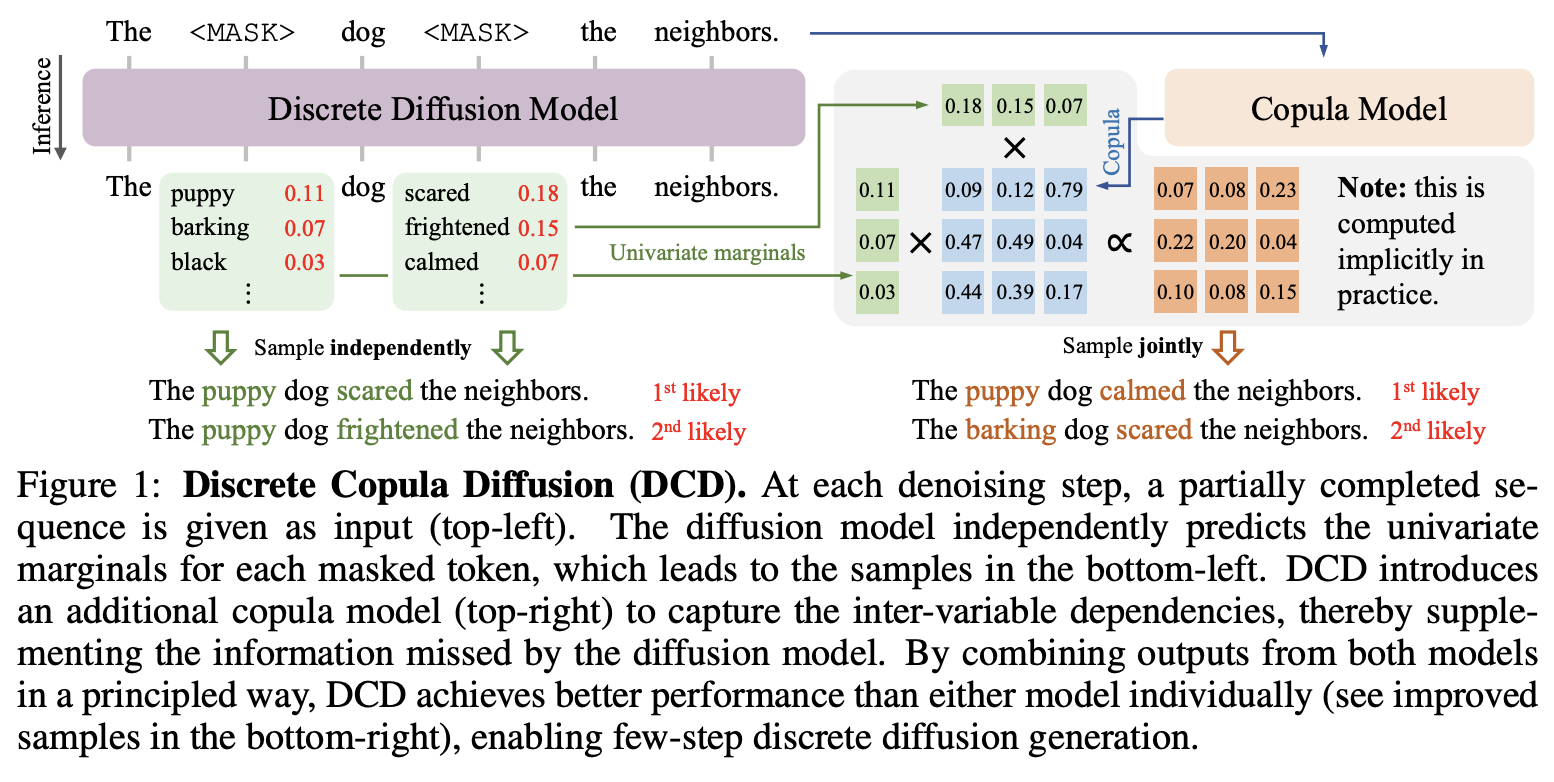
An example of this is (Liu et al, 2024)’s Discrete Copula Diffusion (DCD), an approach where the probabilities of a Masked-DLM (SEDD Absorb) are augmented with that of a much smaller-sized AR-LLM (GPT-2 small) adding information about the joint distributions between tokens. This “enhanced” distibution enables better generation quality in the form of lower generative perplexity while allowing the model to take fewer denoising steps.This is inspired by the concept of a copula model in statistics that parameterises a joint distribution using information from known marginals; which is what we have with the per-step token-level independent distributions from the Masked-DLM. Note however, that there are many details in this work and it might be worth looking into these further, one of which is how an off-the-shelf pretrained AR-LLM (GPT-2 small) can provide the joint distibution information on noisy (masked) data.
Sidenote: I found this book by (Trivedi & Zimmer, 2007) helpful to get a primer on copula modeling. Whilst this approach will require the Masked-DLM and supporting AR-LLM share the same tokenizer, this is supported by the works in the vein of Dream (Ye et al, 2025) and DiffuLlama (Gong et al, 2025) for converting AR-LLMs to Masked-DLMs.
Another is (Xu et al, 2025)’s Energy-based Diffusion Language Model (EDLM), which shares some similarities in the use of a separate energy-based model (EBM) for obtaining information about token dependencies; and one of two ways they propose to obtain such EBMs is similarly through the use of AR-LLMs. Tangentially related here is work such as (Christopher et al, 2025) that go in the other direction, that is to use DLMs to help speculative decoding for AR-LLMs.
📐 4. The sequence lengths have to be fixed and caching can’t be done?
Another limitation of initial Masked-DLMs (and all DLM variants for that matter) is that generation length is a hyperparameter that has to be set in advance (i.e. some length needs to be specified, which is then used to set the noised input, and then the denoising steps can take place over it). This hard constraint is very limiting; for outputs that turn out to be shorter in length, this leads to wasted computation. More significantly, if the ideal output happens to require more tokens than the length than specified, this results in reduced generation quality (through truncation, or via throwing off coherence as the model contorts to denoise within the specified length). At the same time, another issue relates to how the standard KV caching used in AR-LLMsSee this excellent post by Sebastian Raschka, that helps speed generation there, is not directly transplantable to DLMs (due to how tokens can be unmasked anywhere across the sequence at each step, and how the state of the entire sequence at step \(t\) is needed for predicting the distributions of the following denoising step).
There are a number of approaches proposed to address the former (via variable length decoding) as well as the latter (through block-style diffusion). I highlight two recent pieces of work that combine them: (1) BD3-LMS proposed by (Arriola et al, 2025), and Fast-dLLM proposed by (Wu et al, 2025). Both introduce a notion of semi-autoregressive generation using blocks; each block is autoregressively processed up to the point where an end-of-sequence token is generated, and within each block the typical diffusion denoising steps are carried out (see GIF below). For fast-DLLM, they retain the typical DLM bidirectional attention across all blocks during generation and therefore have to rely on approximations for the caching, approximations which they support with analysis of the typical attention patterns across denoising steps. Notably, LLaDA-V – the multi-modal (vision & language) version of LLaDA – has fast-DLLM integrations built into its implementation. On the other hand, the authors of BD3-LMS use a special attention mask that allows attention to be causal across blocks, which then allows them to cache the KV computation of earlier blocks (akin to how it are done in AR-LLMs at token level); as a result their approach does not need to rely on approximate caches, which in theory should guarantee better results than fast-DLLM.
~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~

~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~

~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~

~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ ~
👉 4. What’s next?
This post went into a few of the key issues and considerations faced in the generation (denoising) process of Masked-DLMs, including looking at (i) how informed denoising strategies is used to help improve generation quality, (ii) how step-wise token-level independence is a limitation for faster generation speed together with some of the (early) ways proposed to address this, and (iii) how block diffusion approaches such as BD3-LMS enable variable length generation as well as KV caching similar to what’s done in AR-LLM for efficient LLM inference (which are particularly important for long sequence generation with Masked-DLMs). In the next post, I will take a look into reinforcement learning (RL) for masked-DLMs, covering what the key challenges there are, followed by recent proposals for addressing them; the focus will be on policy-gradient approaches similar to PPO and GRPO, that have recently been instrumental in AR-LLM post-training.