Diffusion Language Models -- Part Two (What kinds are there and how is one trained?)
August 1, 2025
There are three variants of diffusion language models (DLMs), and the nuances of each impact their training, inference and scalability. I think it will be helpful to situate them amongst each other before we proceed further; and so in this post, I will first introduce the variants, discuss their differences as well as what they mean. I will then go on to outline the training procedure for the Masked (Masked-DLM) variant as it is currently receiving significant amounts of attention in researchAnd quite importantly, with useful extensions into multimodality and reinforcement learning already carried out with them., before ending off with a summary of two interesting pieces of DLM research
◼️ (Wen et al, 2025) The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs
◼️ (Prabhudesai et al, 2025) Diffusion Beats Autoregressive in Data-Constrained Settings that surfaced recently along with thoughts on their broader implications. If you wish, you can use these links to skip to the specific sections of this post: 1. DLM variants; 2. Comparing the variants; 3. Training a masked DLM; and 4. Recent findings and potential implications
🎨 1. What variants of DLMs are there?
DLM approaches can be described as being of the (i) Gaussian, (ii) Uniform, or (iii) Masked variants, based on how the original training data instancesfor e.g. an instance could be a sentence such as “dogs are our friends” for the language modeling task. are “corrupted” (or how the notion of noise is conceptualised and how it is introduced into the input during the foward process. . . and hence (by design) the reverse process as well.). The first two are named for the distributions they use to draw noise from, and the third is likely named for a special token (e.g. [MASK]) added to the vocabulary to give a noised state that “masks” the original token. To give a more concrete feel of each variant, I will use the following toy example to illustrate some of them.
Settings for a toy example
Imagine we have a toy language with 13 lexical units in the vocabulary V = {"we", "you", "they", "our", "your", "their", "cat", "dog", "friend", "is", "are", "s", "[PAD]"}, which allows one to form sequences such as "dog s are our friend s", "our dog s are your s", "your cat is our friend" etc.
The special marker [PAD] is used as a filler to ensure that all sequences are of the same length, e.g. "your cat is our friend [PAD]", so that it has the same six-unit length as the other two dog-sentences, allowing us to do batched generations.
◼️ Gaussian-DLM: This variant, also referred to as “continuous-time” in the literature, is the closest in form to the ones that are found in image diffusion modelsSuch as Google’s Imagen, OpenAI’s DALL-E and Stability AI’s Stable Diffusion, so if you are familiar with them, then the Gaussian-DLM models could be quite familiar to you. The architecture here involves: (i) embedding the tokens of a sequence so that each of them are represented with real-valued vectorsThis is similar to the first step in auto-regressive LLMs (AR-LLMs) (for Transformers as well as RNNs)., and (ii) adding to them noise that is in the form of random vectors drawn from a Gaussian distribution \(\epsilon_{t}\) ~ \(N(\mu_{t}, \sigma_{t}^2)\) at each step. Using the toy example, what this means in practice is that we will keep a look-up table for 13 random vectors (one for every unit in our toy language’s vocabulary) and each vector is of a dimension \(d\). So the sequence “dog s are our friend s” will be represented by six token vectors, and we will add noise to each token vector such that every token is completely gaussian at the limit of the forward process i.e. \(t \to \infty\) (or in practice, some defined terminal timestep \(T\) so that the total noise added is known; it is usually set at 1.0 in diffusion models). A few formulations have been proposed for learning these models, including score-matching which appears most commonly, as well as latent variable models and stochastic differential equations, for learning the reverse process (Dieleman et al, 2023). Examples of Gaussian-DLMs include (i) Diffusion-LM (Li et al, 2022) that appeared in 2022 and which first drew attention towards diffusion modeling for text generation, (ii) CDCD (Dieleman et al, 2023), and (iii) PLAID (Gulrajani & Hashimoto, 2023).
◼️ Uniform-DLM: Instead of the real-valued embedding vectors used in Gaussian-DLMs, this approach represents each token of a sequence with a one-hot vectori.e. the vector for each token is a dirac distribution with all probability mass concentrated at the actual token’s index in the vocabulary.; of dimensions the size of the vocabulary; whereby it is 1 at the position of the token in the vocabulary, and 0 elsewhere. Here, the notion of adding noise to the data instanceNote that noise is added/removed independently between each token in the sequence – “We make the assumption that the forward noising process is applied independently across a sequence… the denoising process factorizes independently across tokens.” (Sahoo et al, 2024) is via the application of some transition matrix (\(Q_t\), determining the probabilities for whether the token stays unchanged or to which one of the other vocab units) such that the initially concentrated probability mass in the token vector gradually distributes over all of the other vocab units. At the limit of the forward process, the one-hot vector applied with \(Q_{t=T}\) would give a uniform distribution (i.e. each vocab unit is equally likely; there is completely no useful signal to deduce what the original token was) and also reach stationarity, i.e. additional steps cannot change from the uniform distribution. Examples of this approach include the Uniform versions of the models trained in (Lou et al, 2023) and (Schiff et al, 2025).To extend the Wheel analogy to Uniform-DLM: (i) instead of each panel on the gameboard being two-sided (being either white/blank or a character), they would be |\(V\)|-sided (i.e. as many sides as the vocabulary and without white/blank), (ii) the gameboard will start with some completely scrambled combination of characters, and (iii) at every guess, the contestant can flip multiple panels to any other character in the vocabulary. Another way to look at it could be as a slots machine (see GIF below).
Source: Slots GIF – https://discrete-diffusion-guidance.github.io/
◼️ Masked-DLM: This is also referred to as modeling discrete diffusion with an “absorbing state”, first appearing in (Austin et al, 2021). Essentially, noise is represented by the special token mentioned above for e.g., the sentence “dog s are our friend s” could be gradually masked to “dog [MASK] are our [MASK] s” and finally to “[MASK] [MASK] [MASK] [MASK] [MASK] [MASK]” , i.e. a token in the original sequence is corrupted by being “absorbed” into this special state (rather than transitioning to others). This is an important characteristic of most current Masked-DLMs, i.e. in the forward process, once a token transitions to [MASK], it stays in that state throughout the subsequent steps. Conversely, in the reverse process, once a [MASK] token transitions to a vocab unit \(v\) other than [MASK], it also stays as \(v\) in all subsequent steps.This variant matches the Wheel analogy in the previous post; the white panels correspond to the [MASK] token, behind each white panel is one character and once a contestant makes a correct any guess for it, it cannot be changed. Masked-DLM is the basis for the LLaDA (Nie et al, 2024) and Dream (Ye et al, 2025) models, as well as well as multimodal versions such as LLaDA-V (You et al, 2025) and MMaDA (Yang et al, 2025), It was also explored in SEDD (Lou et al, 2023), which Inception Lab’s Mercury models are reportedly based onThe Mercury technical report (Inception Labs, 2025) state that “Our methods extend (Lou et al, 2023) through careful modifications to the data and computation to scale up learning.”. Although they do not state which of the Masked-DLM or Uniform-DLM variant they studied in (Lou et al, 2023) they ended up leveraging, it seems possible that the Gaussian-DLM approach was taken given the poorer perplexity figures obtained by Uniform-DLM in their work as well as in earlier work..
Light round-up: At the limit \(T\) in their forward processes, each class of DLM can be summarised as follows: for Gaussian-DLMs each token in a sequence can transition to any other token (state) reachable by the accumulated variance of the sampled noise; for Uniform-DLMs, each token can transition to any other state with equal probability; and in the case of Masked-DLMs, each token lands on the special [MASK] token.
Masked-DLM connections with BERT: Recall that BERT (Devlin et al, 2018) – an encoder-only model that could be used for tasks such as cloze-style QAe.g the most likely token after “Paris is the capital of” is “France”. and which is a precursor to the LLMs of today – was trained with a masked language modeling objective, i.e. random portions (~15%) of the sentences in the training data are masked, and the model has to learn to predict the masked words. This is very similar to the Masked-DLM approach, except that in Masked-DLMs this unmasking is done across multiple steps (instead of a single pass), and for the entire sequence (the last Masked-DLM inference step would most closely align with the task in the BERT MLM objective). Accordingly, some work have explored leveraging BERT-style (i.e. encoder-only) models for DLM: see DiffusionBERT (He et al, 2023) which propose further training BERT with time-embeddings with a special diffusion noise schedule to use it à la DLM. See also ‘Comparison to BERT’ in §6 of (Sahoo et al, 2024) for a discussion on this connection.
🍏 2. Apple-to-apple: what’s the benefit of one over another?
There is more focus on Masked-DLM and Uniform-DLM over Gaussian-DLM currently, as the latter has been met with comparably less success (in terms of achievable perplexity).The reason for this is because the question of how to reconcile the noised real-valued vectors in Gaussian-DLM to discrete space is not trivial and required many special tricks for training and inference to work. For instance, it was necessary to use nearest neighbour search and clamping to a valid token vector at every reverse diffusion step in Diffusion-LM (Li et al, 2022) to reach comparable performance with AR-LLMs. In the most recent round of published DLM research (i.e. ICLR and ICML in 2025), significant attention has been focused on Masked-DLM approachesThough it should be noted that interesting work on Gaussian-DLM & Uniform-DLM is also continuing, I think notably in (Sahoo et al, 2025), where they work out a proof that connects Uniform-DLM as a special case of Gaussian-DLM using the argmax operator, and opens up the possibility to leverage techniques in Gaussian-DLM for training and inferencing on Uniform-DLM., as they achieve better perplexity compared to Uniform-DLMNote that lower is better for perplexity; compare the SEDD (Uniform) and SEDD (Absorb) results in Table 1 of (Lou et al, 2025); as well as D3PM uniform vs D3PM absorbing in Figure 2 and Table 2 of (Austin et al, 2021).. Intuitively, this is not unexpected, as it would seem easier to learn an Masked-DLM (where transitions are constrained once the absorbing [MASK] state is reached in the forward process) compared to Uniform-DLM (where transitions at each timestep could be to any other tokens, i.e. a much larger space of posssible transitions).
However, several shortcomings of the Masked-DLM approach have been raised (hence the continued research interests in Gaussian-DLM and Uniform-DLM approaches). Chief amongst them include: (i) the potentially over-restrictiveness of the vanilla Masked-DLM masking/unmasking procedureI use “vanilla” because there are approaches emerging that propose more advanced inference procedures such as remasking that could address this. For instance (Wang et al, 2025); and (ii) the difficulty of introducing classifier-free guidance into Masked-DLMs.
◼️ regarding shortcoming (i): “Self-correction” is a term for referring to how tokens can continue to transition to others over the reverse diffusion steps; it is connected to the “coarse-to-fine” property (in the truest sense) that DLMs are frequently touted to beneficially possess over AR-LLMs. While self-correction is inherently possible in Gaussian-DLMs and Uniform-DLMs given their designSidenote: they could also be steered with predictor-corrector models like in image diffusion models (Lezama et al, 2023), it is not possible with Masked-DLM (without some engineering). Theoretically, this lack of self-correction could give rise to errors in the inference steps, which would then propagateTo give a concrete example, say we start from “[MASK] [MASK] [MASK] [MASK] [MASK] [MASK]”, errors (e.g. in modeling learning) could bring us to “[MASK] [MASK] are your s [PAD]” and since unmasked tokens cannot transition any further, this leaves limited choice but to go to “our dog are your s [PAD]” resulting in a number agreement error.
Sidenote: It could be interesting to carry out a study at-scale of the tokens (and the types of words they form) that get unmasked across the Masked-DLM inference steps – e.g. see Figures 10-15 of (Austin et al, 2023), and establish whether there are any significant patterns in what parts of a sentence/paragraph gets unmasked and fixed first.. That said, some recent studies proposed remasking strategies to address such issues – e.g. (Zhao et al, 2025), (Nie et al, 2024). (Wang et al, 2025) also claim to provably show the soundness of applying remasking without needing to take special considerations into the training and inference of Masked-DLMs. In practice, the LLaDA authors (Nie et al, 2025) were able to reach AR-LLM performance for their model whilst leveraging generation with remasking strategies (see §2.4 of their paper).
◼️ regarding shortcoming (ii): Guidance originates from diffusion modeling for image and refers to conditioning information (for instance a label such as “dogs”, or a text prompt such as “friendly-looking dogs”) we can add to “guide” the reverse diffusion process towards generating an image with certain desired properties.This was initially proposed with the use of gradients from a classifier (Dhariwal & Nichol, 2021) that can identify the classes of the images during training; but since training is over a diffusion process, the classifier had to be trained to be able to identify the classes across the noising process, which can be complicated to achieve. (Ho & Salimans, 2022) established a more efficient and effective to train an image diffusion model for guidance without the need for a separate classifier (classifier free guidance, or CFG) which is now widely used. See this Sander Dieleman post for an overview. For a more visual explanation of CFG (and also diffusion models in general), have a look at this recent Welch Labs-3Blue1Brown explainer. Guidance is useful for DLM too, as a way to steer towards safety and better matching user intent, for e.g. to adhere to style requirements or reflect concepts such as non-toxicity, inclusivity, empathy, neutrality etc. An example of such work is DGLM (Lovelace et al, 2024) which uses a Gaussian-DLM to produce a “candidate” continuation of a prompt plus some guidance condition, whichThe input to the AR-LLM is the probability distribution of the candidate denoised/”refined” by the Gaussian-DLM from noise. is then put through a decoder-only AR-LLM to verbalise.For a quick overview: see Kilian Weinberger’s presentation on the work. However, standard classifier-free guidance (CFG) are designed with diffusion models trained with the score-matching objective (which learns a model to match the score, or the gradient of the log probability density function with respect to the data) in mind. Score-matching in the continuous sense is not used for Masked-DLMsThough there is concrete score matching (Meng et al, 2023) for the discrete case (modified in SEDD (Lou et al, 2023)), it is an approximation and does not address how classical guidance (as in the continuous setting for images) can be applied (without potentially scrambling the discrete semantics). Moreover, recent Masked-DLM work such as in the LLaDA family of models directly set the training objective as the cross-entropy loss on the masked tokens (Eq 3 in (Nie et al, 2025)), a further departure from the score-matching formulation for learning DLMs. hence it is not feasible to transfer existing CFG techniques to Masked-DLMs. Notably however, (Nie at al, 2024) proposed unsupervised classifier-free guidance, a training objective to allow CFG in Masked-DLMs without using paired data (e.g. prompt-continuation, question-answer); they found that unsupervised CFG fine-tuning of an Masked-DLM gives better performance compared to using standard CFG.
🏋️♀️ 3. What is the training procedure for a DLM?
To get a general sense of the DLM training procedure, it will be useful to look at the LLaDA approach as it includes language model pretraining and instructions fine-tuning, both of which are fundamental for general-purpose LLM usage. Note that most work parameterise their DLMs using the Transformer architectureParalleling the trend in image diffusion too (Chang et al, 2022) as well as (Peebles & Xie, 2023), but this is not a must.Alexander Rush has a useful explainer video of diffusion models for text in general. Here I will briefly touch on two key areas of the training procedure: (i) the noising in the forward process, and (ii) the training objective. For more details and code on LLaDA’s training, see their blogpost and codebase.
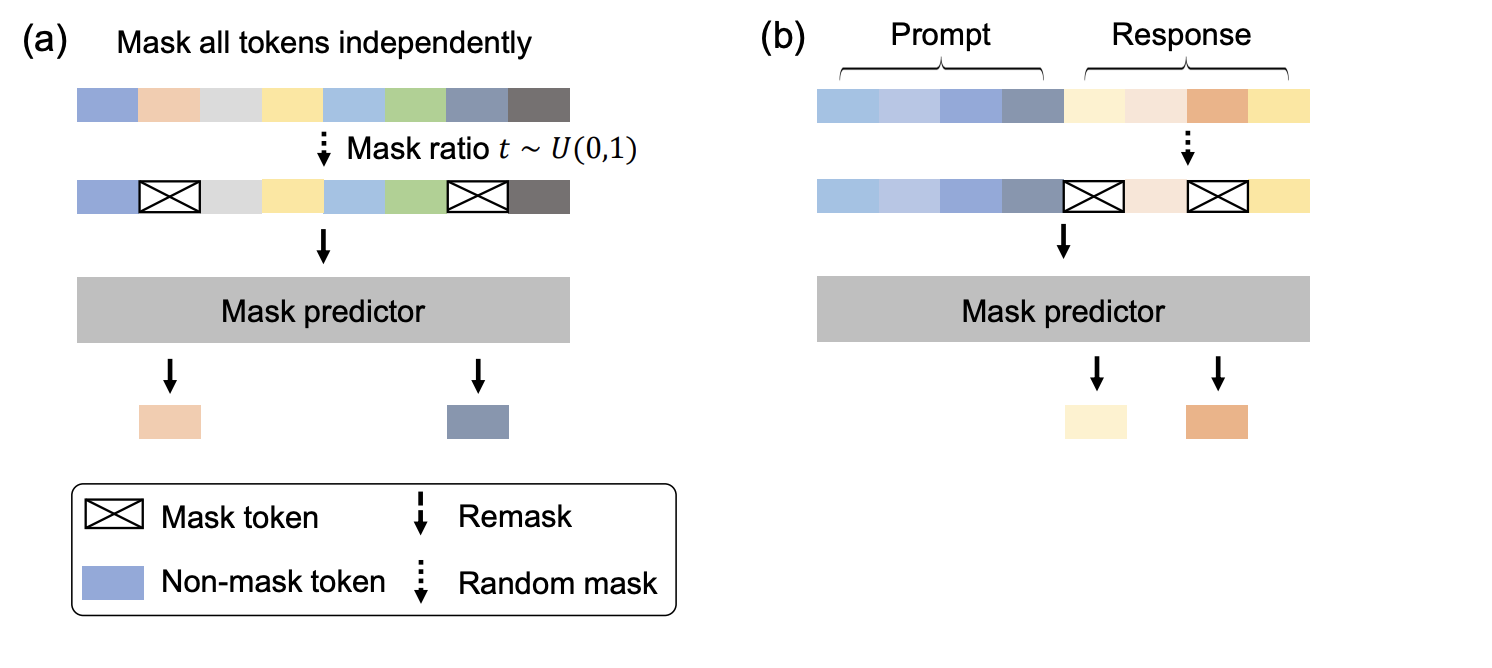
◼️ Noising: The general idea is to sample some noise level for a given data instance (see graphic above for how masking is done for pretraining and for instructions fine-tuning) which will be used to determine the tokens to mask (e.g. in footnote 10 above on the sequence “dog s are our friend s”) in the forward process. The noising schedule (e.g. linear, geometric or even cosine) can impact performance; for instance, if we model it such that masking is at a slower rate as \(t \to T\) in the forward process, then this would align with an unmasking sequence in the reverse denosing process where we unmask comparatively fewer tokens at first before gradually increasing.Intuitively, this makes sense since tokens are unmasked independently of each other at each time step, and given the fixedness in Masked-DLMs unmasking, we want fewer commitments at the start to reduce the unmasking of conflicting tokens, which will go on to compound in subsequent steps. On another note, multiple epochs (together with full-attention over the sequence length at every step drive compute for DLM training up; <=64x, see (Gulrajani & Hashimoto, 2023)) of training over the data are needed in practice, with (almost likely) different noise sampled on the same data instance, is required for DLMs to reach the same level of performance on perplexity as AR-LLMs (which are typically trained with a single epoch over the data); while less efficient to train, it is this procedure that imbues the DLM to be able to generate non-autoregressively.
◼️ Training objective: In the earliest diffusion models, the training objective involves having to compute the evidence lower bound (ELBO)Unlike AR-LLMs which factorise the likelihood of a sequence into conditional probabilities (i.e. probability over the vocabulary at every step) which make it easier to evaluate, likelihood of a sequence (which is how we model in DLM) is intractable, hence the use of ELBO.; subsequently, a simplification to the original ELBO was proposed with the score-matching approach(Ho et al, 2020) showed that the original ELBO in the diffusion objective can be further simplified by modeling the probability distributions as scores (gradient of the log prob with respect to the data), and the objective can be reduced to minimising the mean-squared error of the entries in the predicted score vector and the true score, which is substantially easier to do.. Since the noise level varies across time, it was also included in a time variable (for e.g. as an additional embedding in CDCD). Recently, it was shown (quite concurrently, based on version dates on arxiv) in MD4 (Shi et al, 2024), MDLM (Sahoo et al, 2024) and RADD (Ou et al, 2024) that, for Masked-DLMs, a tighter bound could be obtained by modeling the predictions of the logits at each timestep against the ground truth (“clean data”) labels using cross-entropy, and that it is fine to drop the need to explicitly capture the time variable, which greatly simplifies the training objective (and becomes very similar to the standard AR-LLM training objective). Notably, the use of this cross-entropy objective is validated empirically by the strong evaluations from the LLaDA model, whose training was done with it.
📰 4. What’s come up recently in DLM research?
On another note, two interesting pieces of research have surfaced last week which I think adds to the conversation about DLMs.
◼️ The first is from (Wen et al, 2025) which studies the jailbreaking vulnerability of text and multimodal Masked-DLMs (LLaDA, Dream and MMaDA). They find that these Masked-DLMs (see Appendix C of their paper) “often match or surpass those of autoregressive LLMs in resisting existing jailbreak attack methods”, which is ideal. However, they also found that it is possible to use AR-LLMs (GPT4o or a 7B-parameter Qwen model) few-shot prompting to generate “mid-flight” unmasked sequences (i.e. \(\hat{x}_{t}, 0 < t < T\)) which an Masked-DLM would go on to unmask jailbroken content (see example on right column). Notably, they tested their method on several jailbreaking benchmarks and established similar findings of such behaviour across Masked-DLMs, including going from \(\leq\) 1% success on JailbreakBench to \(\geq\) 99% success. They also found that simply extending the length of the sequence made it possible to bring the Masked-DLM from initial refusal to a jailbreak outcome (see next example on right column). These findings flag the need for further efforts to study DLM jailbreaking, to better understand and find ways to mitigate such safety weaknesses in them.

Source: jail breaking example – (Wen et al, 2025)

Source: jail breaking example – (Wen et al, 2025). This finding indicates some conditional dependence for generating refusal content which is tied to max sequence length seen at training, i.e. this might be resolvable by taking steps to disconnect this dependence during training.
◼️ The other work (Prabhudesai et al, 2025) studies the compute-data Pareto frontier of DLMs and 100 comparable AR-LLMs. Specifically, they trained 100 Masked-DLMs and AR-LLMs (ranging in size from 7M- to 2.5B-parameters) on the English C4 corpus (at data scales of between 25 to 100M tokens) for up to 800 epochs. From their study, they found that initially, at low epoch counts, AR-LLMs outperforms DLMs; but as repeated passes over the data is carried out, DLMs overtake and perform better. Their experiments allowed them to establish a potential scaling law for for DLMs, and also conclude that under data-constrained settings (for e.g. when Internet data peters out, or in sequence modeling for specialised domains/applications where available data could be at smaller scales), a DLM architecture may be better for modeling the data distribution. The findings provide useful insights that help clarify whether (and where) moving to DLMs makes sense. That said, we are still lacking an understanding of the DLM & AR-LLM differences under real-use case evaluationse.g. with suites such as lm-evaluation-harness; in their work they only report loss curves and perplexity (NLL). as well as the impact of methods that have been recent drivers of AR-LLM model improvements (such as training on synthetic data, as well as preference tuning and reinforcement learning) on DLMs.
Some useful resources for diffusion modeling: Firstly, the “Diffusion Models” chapters in:
◼️ Chapter 20 of Deep Learning: Foundations and Concepts. Bishop, C.M., Bishop, H. (2024). Springer.;
◼️ Chapter 25 of Probabilistic Machine Learning: Advanced Topics. Murphy K. P. (2023). MIT Press.;
◼️ Chapter 18 of Understanding Deep Learning. Prince, S. J. D. (2024). MIT Press.
Of the three textbooks, the Murphy one (to my mind, the bible of probabilistic generative modeling for its breadth and depth) has the most substantial coverage of discrete diffusion modeling, and the Bishop one is (in my opinion) the most accessibly written plus it also comes with helpful sections on score matching and guidance; though it helped to triangulate information between the three as much as possible.
Secondly, it also helps to start with the score-matching diffusion models that were developed for image generation and go on to discrete case. To help: the diffusion and flow modules of the CS236 class taught by Stefano Ermon could be very useful for putting the parts on together.
◼️ Stanford CS236: Deep Generative Models 2023 playlist
Finally, this survey paper also goes deep into the various aspects of DLMs:
◼️ Discrete Diffusion in Large Language and Multimodal Models: A Survey
Some notes: It seems reasonable to consider combining Uniform-DLM and Masked-DLM, after all the latter is just adding an additional state [MASK] and enforcing fixedness once this state is reached/exited. I am wondering if it might make sense to add the [MASK] token as well as permit transitions to and from it across the timesteps (i.e. Uniform-DLM+[MASK]), but with some constraints that the overall ratio of [MASK] tokens must monotonically increase over time in the forward process, which could address the “self-correction” limitation of Masked-DLM (see above). (Austin et al, 2021) (see Appendix A.2.6 and B.2.1 as well as Figure 4 (upper) there) stated that they carried out some ablations on the text8 dataset that touched on this – for e.g. by applying \(e_m\) a separate one-hot vector with 1 on [MASK] and 0 elsewhere – but do not seem to have included the results to show how Uniform-DLM+[MASK] performs over Masked-DLM. Although this change might impact the simplification of the loss objective to the use of cross-entropy against ground truth tokens as established by MD4, MDLM and RADD. (see for e.g. §3.1 of the RADD paper)
👉 4. What’s next?
In this post, I have covered the three broad classes of DLMs, discussed what their differences mean, then briefly described the training procedure of Masked-DLMs, before ending on some recent DLM research and their broader implications. In the next post, I will walk through the reverse process used for generation in DLMs, situate generation with DLMs against existing efficient serving methods for AR-LLMs, and then look at the a few recent advanced sampling techniques proposed (such as block-wise/semi-autoregessivity and caching). In the post after that, I will cover preference tuning and reinforcement learning of these DLMs.
Update (16 August 2025): (1) precise DLM’s 64x more FLOPs statement, (2) refine Training objective subsection.