Diffusion Language Models -- Part One (Introduction)
July 20, 2025
Language modeling with diffusion architectures is gaining traction and there are several promising indicators for further adoption. Since I have been on a deep dive into diffusion modelingImpetus: the spark to look into diffusion language models came to mind during a presentation on multimodal AI at Lorong AI https://lorong.ai/ (they do a very nicely curated set of expert talks across wide swathes of AI and AI-adjacent topics). Whilst sitting in one on how vision-language models (VLMs) may be relevant to actions planning in robotics, and how latency is crucial for such uses, I started to wonder about non-autoregressive approaches, especially diffusion (which is known for better consistency and potential for speed). It also helped that it was Google’s I/O week and amidst the coverage of their various launches were mentions of a diffusion demo (see below). – including some experiments for reinforcement learning (RL) post-training of a diffusion language model (DLM), I thought to share what I have come across in a series of posts; which I am planning as (at least) a four-parter, to be gradually released over the next few weeks.The plan is for updates each week. There are already well-written posts on DLMs: one by Xiaochen Zhu (Apr 2025) and one by Sander Dielman (2023), so I will not reinvent the wheel and will focus mostly on outlining and explaining DLM developments since then/as yet covered. My focus will be on diffusion for textEspecially masked diffusion language models (MDLM), a variant whereby a special [MASK] token is used (also termed an absorbing state; in the forward process, MDLMs noise the original sequences by transitioning tokens to this state – i.e. [MASK]). Training and sampling has been found to be easier when modeling the diffusion process for discrete sequences in this way.; which is the modality I am most familiar with; although these models can be applied to discrete sequences in general as well as to, or together with, other modalities (e.g. vision – which diffusion models were originally developed on, as well as audio). In this first post I will introduce DLMs briefly and outline why I see them as promising.
📝 1. What are DLMs? How are they different from current LLMs?
Diffusion architectures are designed around a training and inference procedure that involves a forward as well as a reverse process. In the forward process, random noise is added to some original input (e.g. a real image or a human-written text) and repeatedly done so until it is entirely noised (i.e. the structure that was in the input is completely lostIn the form of white noise for images; gibberish (or complete whitespace in the MDLM case) for text.). What we want is a model that can seek to reverse this noising process; and if the noise in the forward process has been carefully added (minute amounts at each step; following an increasing schedule; and from a distribution easy to sample from), then the learning of the model is made relatively easy. Subsequently, it will be possible to start from complete noise as input, denoise it over some number of steps using the learned model, and arrive at a state where meaningful structure is restored (et voila, we would have obtained a realistic sample).

Generated with ChatGPT.
To give a more intuitive sense of how DLMs work, I will draw on Wheel of Fortune (Wheel)Sidetrack: For an introduction, see this Wikipedia entry. for an analogy. To set the scene: imagine it is a weekday evening, a game with Pat Sajak (or Ryan Seacrest if you prefer) and Vanna White is running, a sole contestant remains on the show. The round starts and the board shuffles to reveal a sequence of white panels, and Pat/Ryan gives the category: “Living Things”. So far this corresponds to the forwards noising process described above.
In this game you are Pat/Ryan (who gave the category), and the contestant is your favourite LLM (ChatGPT, Claude, Deepseek, Le Chat etc) or a DLM. The task is for the contestant to correctly guess the characters behind each of these white panels on the board, based on the category.Sidetrack: In fact we can drop the wheel; there is no revealing of R-S-T-L-N-E on the board either; and guesses are for tokens not characters. Think also of the category along the lines of the context/prompt we typically give to LLMs and the white panels on the Wheel board as the LLM/DLM’s response to your context/prompt. The LLMs (e.g. ChatGPT) that we are familiar with are modeled in an auto-regressive manner (AR-LLMs from hereon), i.e. no matter what, they go about solving the task by making a sequence of guesses that go from left to right, one character/token at a time.If you think about it: such a strictly left-to-right strategy is unlikely to be adopted by a human player. A DLM, on the other hand, solves the task by making a sequence of guesses (the reverse process above) – each guess can be for anywhere across the sequence and can also be for multiple tokens at a time. At each step of the guessing, a DLM makes its next guess based on what it has already unmasked in the sequence.
Although this is a major simplication – for now, I have glossed over many details and important nuances for DLMs – it should have hopefully given you a rather concrete sense of how AR-LLMs/DLMs generate text conditionally. As you can see, the AR-LLM and DLM generate text in ways that are quite different.
Some other caveats for the Wheel analogy: it is not perfect for AR-LLMs, because they only know to keep guessing characters/tokens until some special stop state has been reached (i.e. without knowledge of how many characters/tokens left to guess; the white panels). It is also not a perfect analogy for DLMs because in practice (and also a source for their appeal) they predict more than one character/token at a time.
🤩 2. What is the appeal of DLMs?
A major appeal of DLMs is its non-autoregressive manner (NAR) of generationTechnically, we can make a DLM autoregressive – we can enforce a left-to-right denoising during inference; and we can modify the DLM training to go to a noising schedule that runs right-to-left.. For text, this reflects more closely how long-form writing (typically requiring planning) takes place. In constrast, the auto-regressive (left-to-right) manner of generation places a very strong constraint, and there has long been grouses about it, as well as claims that it is unlikely to bring us to stronger machine intelligenceYann LeCun then-controversially stated at a few venues in 2023 (see below a slide he reposted on X) that AR-LLMs, in having to generate tokens one-by-one, encounter errors that compound. If the generation path veers into a region away from the right answer, there is no (straightfoward) way for the AR-LLM to get to the right answer. It is worth noting however, that methods to induce test-time-scaling (with post-training such as iterative supervised fine-tuning or RL for reasoning) mitigate at least a part of this issue, without having to switch to NAR; (look under `Why Yann Lecun was wrong (kind of)’ in this post by Jack Morris)..

Source: Slide – Yann LeCun’s X post in 2023
From this non- autoregressivity springs other benefits. Since DLMs are not limited to generating one token at a time, (i) there is potential for significant speed-up with itI am using ‘potential’ here because efficient serving methods for AR-LLM such as KV caching and speculative decoding do not transfer directly to DLMs. There is a trade-off currently – even if a DLM takes fewer steps than AR-LLMs for inference, each of the DLM’s steps requires computing over the full target sequence length. It is not yet clear if similar efficient serving methods are available and can work well for DLMs. Furthermore, (at least for the current generation of DLMs from academia) running more denoising steps up to max sequence length is necessary for DLMs’ peak performance (see Figure 5 of Appendix B6 of the LLaDA paper).; and (ii) they can achieve better conditional control and consistencyDiffusion-LM Improves Controllable Text Generation (Li et al, 2022). Furthermore, generating in an NAR and denoising manner also enables alternative decoding strategies such as infilling. In the GIF below, some prompt is shown at the start for the DLM to complete, followed by a constraint that must be met at the end; the task is to generate some sequence of text between them (hence the term `infilling’See also inpainting for vision models.), which is not easily possible with an AR-LLM (without restarting inference at the point where the edit(s) end). Infilling is useful in code generation – for instance, a program could be generated and an engineer can make targeted modifications (say a function) anywhere within the program, and then generation can continue based on this modified state. I find this infilling capability of DLMs particularly attractive; its usefulness is not restricted to code generation, and having it for generative modeling allows for application design choices that can facilitate mutually beneficial human-machine collaboration; if done right, these infilled edits are useful for improving model outputs (towards general model capabilities and for meeting localised/personalised preferences).
🚦 3. What are the signals for DLMs’ potential?
Firstly, two commerical-grade models are already available. They provide strong support for the potential of DLMs; I have tried demos of both, and they are very compelling for general purpose LLM usage.
◼️ The first to arrive was Mercury. In fact, the Mercury models are already products accessible via APIhttps://platform.inceptionlabs.ai/docs#models. They are from Inception Labs, a start-up whose co-founders are Stefano Ermon (Stanford) and his former students Aditya Grover (UCLA) and Volodymyr Kuleshov (Cornell)Ermon - X/website; Grover - X/website; Kuleshov - X/website.. Notably, the founders are behind the research for many of the diffusion modeling innovations (for both image and discrete sequences) in recent years. Their code-focused DLM (Mercury Coder Mini/Small), that was released in February 2025TechCrunch article on Inception Labs, has been independently benchmarked as being able to generate at >1,000 tokens per second; up to 10x faster than heavily optimised closed LLMs like GPT-4o Mini and Claude 3.5 Haiku (see chart below). Their`Mini’ code model is also currently (July 2025) joint first on Copilot Arenahttps://lmarena.ai/leaderboard/copilot. In June 2025, they also released a general chat (like ChatGPT and Claude) modelInception Labs release .
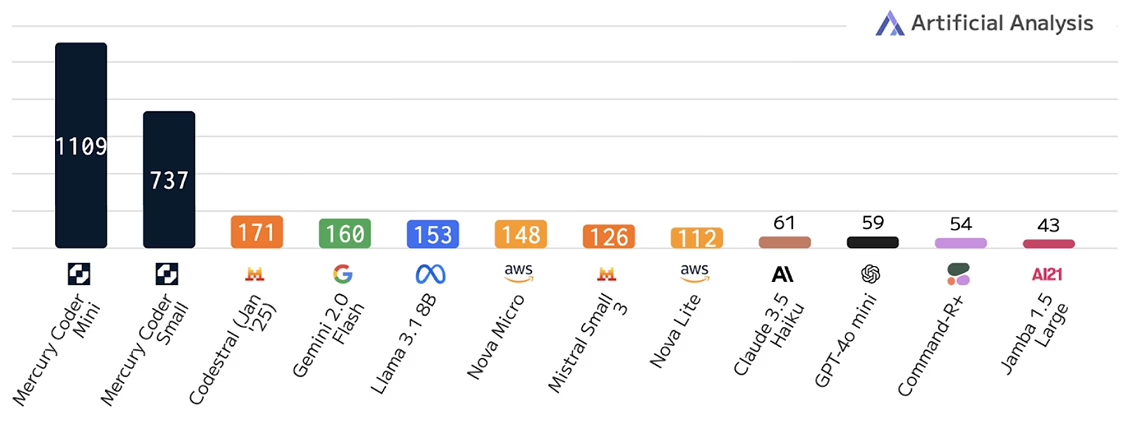
Tip: I recommend checking out Yupp.aihttps://yupp.ai; They have a very unique and practical value proposition – see this Wired profile of Yupp when they came out of stealth in June 2025. See the research thinking (including on global-scale localisable evaluations) behind Yupp here as well as on their blog. , which you can use to easily test the Mercury modelsFind the Select a model button and search for and add Inception Mercury (the general chat model). (or any other model) side-by-side against more than 600 other (open as well as closed-source) LLMs, including the latest and previous model versions from OpenAI, Anthropic etc.
◼️ The second is from Google DeepmindThis demo is less accessible; you will have to sign up for it via a waitlist. which landed in May 2025. They claim that their DLM generates up to ~1,500 tokens per second and achieves results nearly matching or even outperforming Gemini 2.0 Flash-LiteGemini 2.5 Flash Lite is the smallest of the Gemini models (i.e. first come Pro, Flash and then Flash Lite). for five out of six coding benchmarks evaluated againstExcept for SWE-Bench Verified, where the diffusion model obtained 22.9% vs the 28.5% obtained by Gemini 2.5 Flash Lite, as well as stronger math performance (AIME 2025).
~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~
Secondly, open-source/weights DLMs have been trained and released by academia. This signals accessbility to training such models, at compute-levels available there. These models are performing favourably against comparable AR-LLMs on evaluations over a wide range of real-use caseslm-evaluation-harness, and not just on measurements of perplexity alone. Such models include the LLaDA familyhttps://github.com/ML-GSAI/LLaDA; from Renmin University of China, BDAI and Ant Group, which underwent pretraining and supervised fine-tuning at scales similar to recent AR-LLMs like Llama 3 (i.e. pretrained with Internet data at trillion token-scale – for denoising instead of next-token prediction as in AR-LLMs, as well as supervised fine-tuned on millions of instruction-answer pairs for instruction-following). Notably, parallel efforts to use AR-LLMs’ weights to initialise models for DLM trainingSee DiffuLlama and Dream. are also showing promising performance – these allow us to bypass the need to train DLMs from scratch, and would be a way to further leverage all the training that have already been expended on existing AR-LLMs.
~~~~~~~~~~~~~~ ~~~~~~~~~~~~~~
Thirdly, solutions are also emerging for preference tuning and RL post-training of DLMs. The former have been important for enhancing safety and instruction-following of AR-LLMs, and the latter is increasingly important for unlocking their reasoning capabilities. Work done in this space include: (i) DiffuCoderhttps://github.com/apple/ml-diffucoder; from the University of Hong Kong and Apple.; (ii) diffu-GRPOhttps://dllm-reasoning.github.io; from UCLA and Meta AI.; and (iii) Variance-Reduced Preference Optimization (VRPO) in LLaDA 1.5https://ml-gsai.github.io/LLaDA-1.5-Demo; from Renmin University of China, Tsinghua and Ant Group.. Given the recent developments in these spaces for AR-LLMs, these are likely to be interesting areas to explore with DLMs.
👉 4. What’s next?
In summary, I have briefly introduced diffusion language models (DLMs) which is an emerging approach for an alternative to current auto-regressive LLMs. I also discussed why DLMs are appealing and highlighted some indicators I believe show their promise. In my next post, I will go into how DLMs are trained/converted from AR-LLMsAs in the case of models like Dream., going a bit deeper into the technicals. Following that I will examine the ways to sampling from these models, with a discussion on possible implications on efficient serving.